
Squashing in Git
In this post we demonstrate different ways to squash commits in Git. The term squashing refers to consolidating multiple commits into one single commit, for the purpose of simplifying the project history.
There are several ways to perform this task in Git.
Interactive rebase
> git rebase --interactive
The Squash Command
One, if not the most used way to squash multiple commits is to perform an interactive rebase in combination with the squash command.
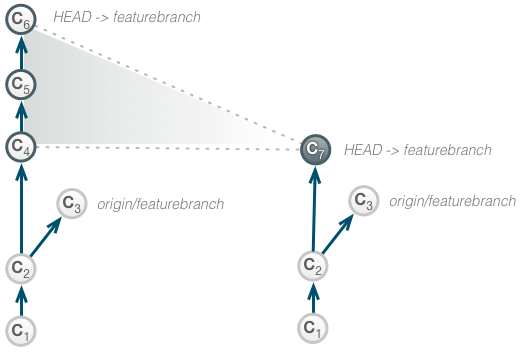
Let’s assume the following repository state:
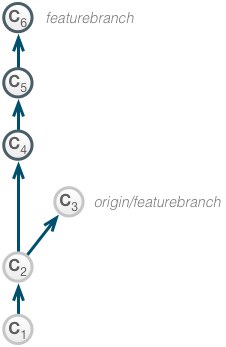
An engineer is doing a local implementation in branch featurebranch concerning feature ABC.
The local branch diverged from the remote (tracked) branch after commit C2.
After implementing the feature, the change is to be squashed and rebased to create a flat and simple timeline.
Being in branch featurebranch, the developer stats an interactive rebase:
git rebase --interactive
When asked by Git what to do with the 3 commits, the engineer tells Git to pick the first one and squash the others into the first one.
> pick C4 > squash C5 > squash C6
Git will combine all commit messages. There won’t be references to the squashed commits and the squashed commits won’t be reachable from any ref.
Hence, they will be removed by the next garbage collection. The new commit message will be a combination of all the messages used for the squashed commits.
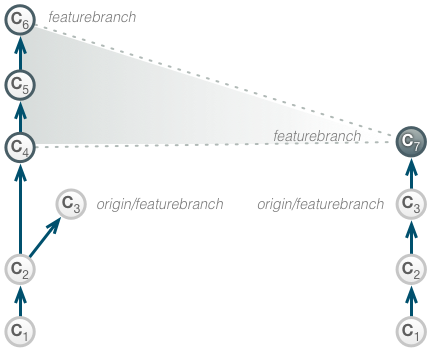
After that, the engineer pushes the changes to the remote repository. The result is a flat graph including a single change (C7) that contains of all the local work done by the engineer. Information about the individual commits is lost; specifically time information is changed, as C7 will have a new author and commit time stamp referring to the time of the rebase.
Advantages
Rebasing is common practice to prevent merges if local and remote (tracking) branches diverge. It ensures a flat timeline which is more appealing and easier for the engineer to understand.
Furthermore, using squash commits keeps all the changes together, which again makes understanding events in the history much easier.
Disadvantages
Every time one combines multiple events into one single event, data is lost. In this particular case, we lose information about the authors of the original commits, timing information when those changes took place and as a result how long it took to develop this feature. In process analysis, the problem of tangled changes is well known and a hard problem. Hence, if engineers rely on process analysis, squashing commits poses a risk to the ability to compute those metrics.
The Fixup Command
We expressed a lot of concerns about squashing commits, as tangled changes have a negative impact on process analysis. Yet, incomplete fixes pose a similar problem.
Especially in defect prediction, counting fixes on a source code artifact is biased by incomplete fixes. Distributed version control systems encourage commits of unverified and potential incomplete fixes in private branches as there is no harm and testing and improving the changes afterwards before merging them in the next integration branch. One might argue that combining (squashing) those changes before integration would even help process analysis.
Git already provides a feature for this scenario: the fixup command.
The fixup command behaves almost the same as the squash command, except that it doesn’t preserve the original commit messages.
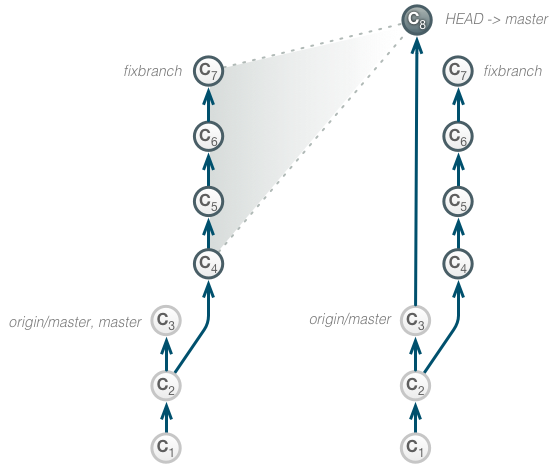
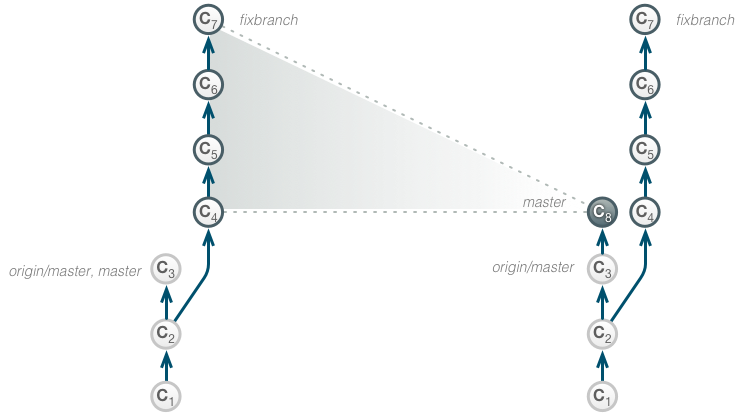
At C2, the developer has created a new branch fixbranch to work on a bug fix. She performs a series of changes (C4-C7) to complete the fix, which leaves us with the following repository state:
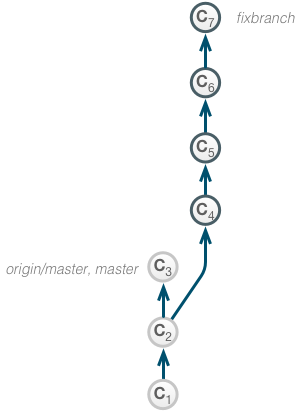
Now the changes are to be squashed and integrated into the master branch.
We start an interactive rebase in our fixbranch and change the commit message of the resulting squash commit.
git rebase --interactive master fixbranch
> reword > fixup > fixup > fixup
After that, we fast-forward merge the squash commit into the master branch and delete the fixbranch.
git checkout master git merge --ff fixbranch git branch -d fixbranch
Advantages
The advantages are the same as for rebasing using the squash command. However, in the case of incomplete fixes, squashing those partial fixes to a complete fix brings advantages, e.g. in defect prediction models that rely on bug counting.
Disadvantages
In the case of fixups, only the changes by the engineer performing the rebase should be combined. Thus, no author information is lost. Still, the problem of original timing information loss persists.
The Onto Option
The –onto option allows to rebase changes onto a different branch, i.e. not the branch the branch to be rebased was created from.
In this example, a new version of the product is developed in the nextversion branch. A developer spawns of a new branch bugfix from the nextversion branch to perform some corrective task.
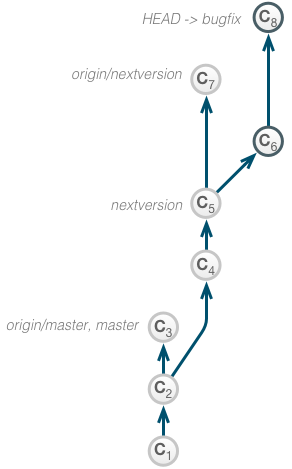
After completing the fix, the changes are to be squashed. Then, the fix is to be applied to the master branch first and later back-ported to the nextversion branch. To accomplish this task, an interactive rebase is performed.
git rebase --interactive --onto master nextversion bugfix
And again he squashes the commits as seen in the fixup example but has them rebased onto the master branch in the process.
> reword > fixup
Now, the engineer can fast-forward integrate the bugfix branch into master and delete the bugfix branch.
git checkout master git merge bugfix git branch -d bugfix
Finally, the fix is merged back into the nextversion branch.
git checkout nextversion git merge --ff origin/nextversion git merge master
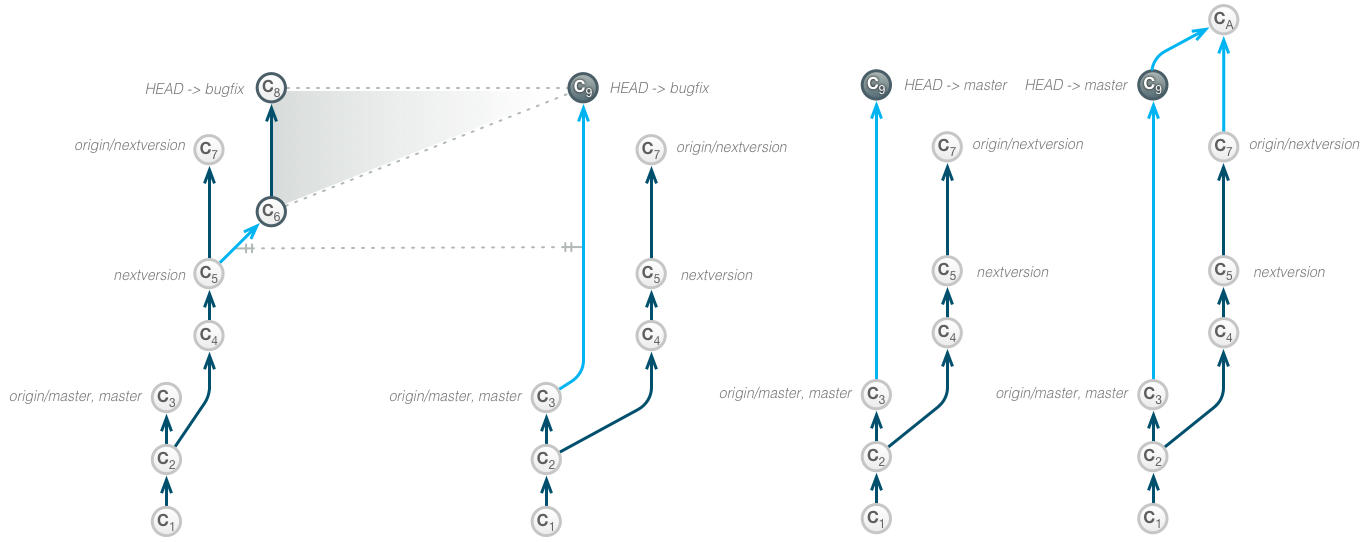
Merge squash
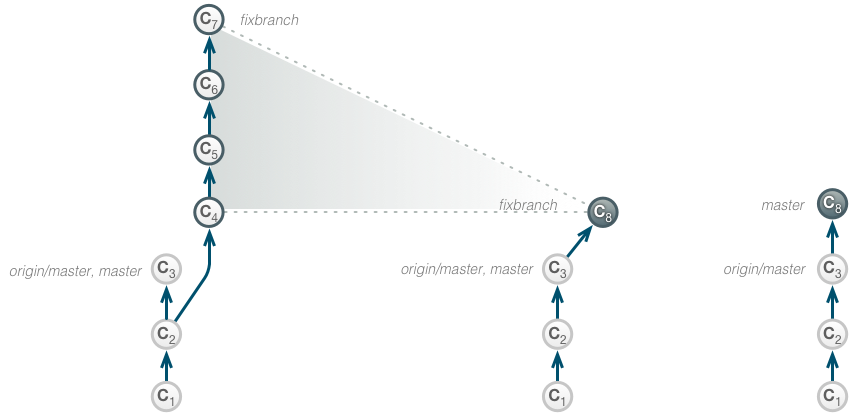
Typically, during a merge, a new commit is created that has 2 or more predecessors in the graph. However, using the –squash option will not create any commit but apply all the changes that would result from the merge to the index. Going back to the example in the fixup section:
The developer performs a squash merge, resulting in a new commit C8 as the product of the changes performed in C4-C7. The original commits are being preserved. The commit message and time stamps are being set by the commit after the merge.
git checkout master git merge --squash fixbranch git commit -m '[BUGFIX] Fixing BUG-123: Invalid response to message X.'
Advantages
This is a very easy and quick way for squashing changes and integrating those into the timeline. Another obvious effect is that the original commits are preserved.
Disadvantages
At the same time, this can also be a disadvantage when analyzing the project history. The changes occur now twice in the project’s history which can introduce bias in process analysis metrics.
Further, the newly created squash commit is disconnected from the original commit as there is no explicit or implicit link between those.
Author and timing information is lost again and cannot be recovered from the merge commit. However, this information is still present in the repository, but requires to recover the links to the original commits.
Squashing using reset
Git’s reset command can manipulate the state and the head ref of the local checkout. One can use it to reset the head of the current checkout to the commit previous to the series of commits one wants to squash.
Squashing your last X commits in the current branch.
As an example, we use the same scenario as the one in the rebase section:
The developer wants to squash commits C4, C5 and C6 in the current checkout of branch featurebranch. To accomplish this, she resets the current HEAD to C2.
None of the changes will be lost, as the current state is preserved, but the previous HEAD is updated to point to an older state.
The changes now only need to be committed. In this example, we supply all of the previous commit messages to the commit message.
git reset --soft HEAD~4
git commit --edit -m "$(git log --format=%B --reverse HEAD..HEAD@{1})"
Advantages/Disadvantages
The advantages and disadvantages are pretty much the same as for interactive rebasing. One might argue that resetting is a concept that is not specific to branches and easily allows to squash the past X commits without further reference points.
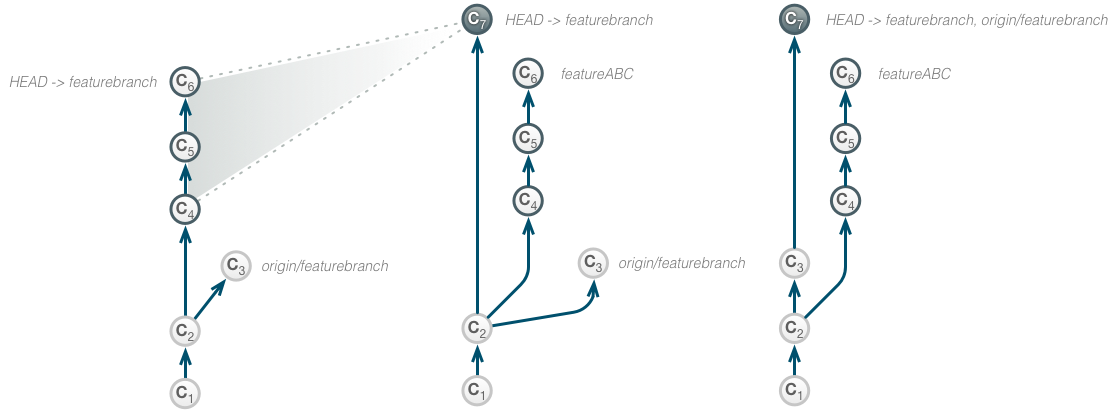
Squashing your last X commits, keeping the original commits and referencing them.
We assume the same scenario as before, but the engineer wants to ensure that the original commits are not being discarded. Further, she wants to explicitly reference the changes in the squash commit.
She first creates an additional branch featureABC. This way, there will still be a ref to the tip of the change series.
git branch featureABC
Then she resets the head to the state 4 commits ago, as in the previous example. Again, the changes are already applied and won’t be lost.
git reset --soft HEAD~4
Then she commits the squashed changes. Further, she retrieves the commit messages of the squashed commits and refer to their hashes. Then she rebases her changes to flatten the timeline again and pushes her changes to the remote.
git commit --edit -m"$(git log --format='SQUASH: %H%n%B' --reverse HEAD..HEAD@{1})"
git rebase
git push
Advantages/Disadvantages
Here, the situation is the same as in the previous example, except that the original commits are being preserved and the commit message of the new commit contains references to the original commits.
Cherry-picking a series
Obviously, we can also cherry-pick commits to perform a squash. This way of squashing comes with the same side effects as a merge –squash does. However, cherry-picking also allows us to exclude certain commits and not merge a whole branch.
The scenario is the same as in the merge –squash example:
The engineer switches to the master branch and, in this case, cherry-picks all the changes from the fixbranch. After that, he commits the changes using a descriptive commit message.
git checkout master git cherry-pick -n ..fixbranch git commit -m '[BUGFIX] Fixing BUG-123.'
Advantages
The advantage of cherry-picking is the ability to also squash individual commits, rather than only series of changes.
Disadvantages
Again, changes are now present multiple times in the repository which can lead to issues when computing certain metrics on the project’s history. Although the original commits are still present, there is no link to that information and models based on author or timing information will be biased.
Conclusion
There are several ways to combine changes in Git featuring different work flows and different results with several advantages and disadvantages. It very much depends on what you want to achieve and what you intend to do with the data in your version archive. All of the above examples use high-level Git commands to manipulate the underlying data in Git’s internal storage. You can also use low level commands and build your own Git commands to perform these tasks such that your project’s conventions or your data analyst’s requirements are met (just put a git-mysquash script on your path to extend Git with a mysquash command).
From our experience, there is no perfect solution to data loss from commit squashing. Squashing a series of local fix attempts might even help analysis, as it combines partial fixes into a complete fix (fixup). However, if feature implementations are being squashed, analysis relies on preservation of the original commits and metadata that links those commits to the squash commit. At a first look, squashing might make the history easier to read. Yet, due to the lack of explicit links, a lot of what’s going and where changes came from can be hard to determine—even manually by engineers.
No Comment
You can post first response comment.